-
[검색 엔진] Python + Django + ElasticSearch 활용 검색 엔진 만들기Search Engine 2023. 4. 1. 01:11728x90
데이터 파이프라인 실습을 하려고 했지만 문제가 발생(..)해 우선 실습 완성 경험을 만들어보고자 검색엔진을 만들어보려고 한다.
※ 너드팩토리 님의 블로그(https://blog.nerdfactory.ai/2019/04/29/django-elasticsearch-restframework.html)를 참고해 실습을 진행하였다.
Django
Django는 Python 기반의 웹 프레임워크로, 미리 만들어진 강력한 라이브러리들을 보유하고 있어 좀 더 쉽고 빠른 백엔드 서버 구축이 가능해진다.
ElasticSearch
Apache Lucene 기반으로 개발된 오픈소스 분산 검색엔진으로, 자동완성, 다국어 검색, 철자 수정, 미리 보기 등 Lucene의 강력하고 풍부한 기능을 대부분 지원한다. 특히 기존 DBMS에서 다루기 어려웠던 전문 검색, 문서의 점수화를 이용한 정렬, 데이터 증가량에 구애받지 않는 실시간 검색 등을 ElasticSearch를 이용해 구현한다.
또한 RESTful API를 지원하여 URI를 사용한 동작이 가능하고, 필요한 기능에 대한 plug-in을 쉽게 설치하여 기능을 확장할 수 있다.
실습 순서는 이러하다.
1. 기본 Django 서버 구성
2. ElasticSearch와 연동하여 백과사전 검색 기능 구현
3. 검색 결과의 문제점
4. 문제점의 해결 방법
python -m venv myvenv myvenv\Scripts\activate우선, myvenv라는 이름의 가상환경을 지정하고 myvenv 내 Scripts를 활성화시킨다.
django-admin startproject server_project cd server_project python manage.py startapp search_appdjango를 설정하고 server_project라는 이름으로 프로젝트 폴더를 생성하고, search_app이라는 애플리케이션을 만든다. 이때 manage.py는 python 형식에서 작성된 애플리케이션 생성 방식을 표현한 파일이다.
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', # Django REST framework 사용을 하기 위함 'search_app' # 이전에 생성한 애플리케이션 ]VSC를 켠 다음 server _project 폴더 내에 위치한 settings.py을 실행하고, rest_framework와 search_app을 넣어준다.
이렇게 한다면 검색엔진 구현 실습을 위한 Django 구성은 완료된 것이다.
Elasticsearch와 연동하여 백과사전 검색 기능 구현
이 기능 구현을 위해 다음과 같은 순서로 진행된다.
1. Python ES API, nori 한글 형태소 분석기 설치
2. 인덱스 설정 및 생성
3. 데이터 삽입
4. view 구현
5. url 설정
6. 검색 결과 확인
1번부터 문제가 발생했다.
Python ES API 설치 과정 중에,

계속 오류가 발생한다..

이쯤에서 명심하자.
pip install elasticsearch : python에 ES API를 설치하는 것
내가 해야했던 일 : Local에 elasticsearch를 깔아서 경로를 진짜 옮겨줘야 한다.
아무튼 이렇게 하면 Python ES API 설치 및 Elasticsearch-plugin 중 하나인 nori를 설치했다.
인덱스 설정 및 생성
Elasticsearch는 문자열을 토크나이징해서 인덱스 하기도 하고, 문자열에서 중요한 단어만을 토크나이징해서 인덱스하는 등 유연하게 다양한 방식으로 인덱스를 생성해서 전문 검색에 뛰어나다. 이를 활용해서 한국어 백과사전 검색에 적합한 인덱스를 생성하기 위해 nori를 이용, 데이터를 토크나이징 해보자.
search_app 디렉터리에 setting_bulk.py을 생성하여 따로 구현한다.
from elasticsearch import Elasticsearch es = Elasticsearch() es.indices.create( index='dictionary', body={ "settings": { "index": { "analysis": { "analyzer": { "my_analyzer": { "type": "custom", "tokenizer": "nori_tokenizer" } } } } } } )json 형식으로 body에 입력이 되는 것을 알 수 있다. 다음으로는 mapping 설정을 진행한다.
mapping
RDBMS의 스키마 개념과 흡사. Elasticsearch의 인덱스에 들어가는 데이터의 타입을 정의하는 것.
mapping 설정을 직접 해주지 않아도 Elastic에서 자동으로 mapping이 만들어지지만 사용자의 의도대로 mapping 해줄 것이라는 보장을 받을 수는 없다. mapping이 잘못된다면 Kibana와 연동시에도 비효율적이기에, Elastic에서는 mapping을 직접 하는 것을 권장한다.
이 때, 각 필드의 타입을 정의하고 위에서 설정해준 my_analyzer로 title과 content를 분석할 수 있도록 설정한다.
# search_app/setting_bulk.py es.indices.create( index='dictionary', body={ "settings": { "index": { "analysis": { "analyzer": { "my_analyzer": { "type": "custom", "tokenizer": "nori_tokenizer" } } } } }, "mappings": { "dictionary_datas": { "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "my_analyzer" }, "content": { "type": "text", "analyzer": "my_analyzer" } } } } } )데이터 삽입
백과사전의 일부를 데이터셋으로 활용하라고 해서 NAVER API를 활용해 백과사전 json 파일을 만들었다. 하지만 포스트대로 완전히 만들지는 못했고, 다만 주어진 형식에만 따라 가려고 노력했다.

dictionary.json # search_app/views.py from django.shortcuts import render # Create your views here. from rest_framework.views import APIView from rest_framework.response import Response from rest_framework import status from elasticsearch import Elasticsearch class SearchView(APIView): def get(self, request): es = Elasticsearch() # 검색어 search_word = request.query_params.get('search') if not search_word: return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': 'search word param is missing'}) docs = es.search(index='dictionary', doc_type='dictionary_datas', body={ "query": { "multi_match": { "query": search_word, "fields": ["title", "content"] } } }) data_list = docs['hits'] return Response(data_list)#searchapp/setting_bulk.py from elasticsearch import Elasticsearch es = Elasticsearch() es.indices.create( index='dictionary', body={ "settings": { "index": { "analysis": { "analyzer": { "my_analyzer": { "type": "custom", "tokenizer": "nori_tokenizer" } } } } }, "mappings": { "dictionary_datas": { "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "my_analyzer" }, "content": { "type": "text", "analyzer": "my_analyzer" } } } } } ) import json with open("dictionary.json", encoding='utf-8') as json_file: json_data = json.loads(json_file.read()) body = "" for i in json_data: body = body + json.dumps({"index": {"_index":"dictionary", "_type": "dictionary_datas"}}) + "\n" body = body + json.dumps(i, ensure_ascii=False) + '\n' es.bulk(body)# searchapp/urls.py from django.contrib import admin from django.urls import path from django.conf.urls import include urlpatterns = [ path('admin/', admin.site.urls), path('', include('search_app.urls')), ] from search_app import views urlpatterns = [ path('', views.SearchView.as_view()), ]django를 연결하고, 만든 searchapp 디렉터리 내 python 파일 중 손댄 파일만 코드로 표시했다.
이렇게 urls.py까지 지정하고 나면 Django는 localhost인 http://127.0.0.1:8000/ 로 들어오는 모든 접속 요청을 search_app.urls로 전송해 추가 명령을 찾을 것이다.
검색 결과 확인
Postman을 활용하여 개발한 API를 테스트한다.
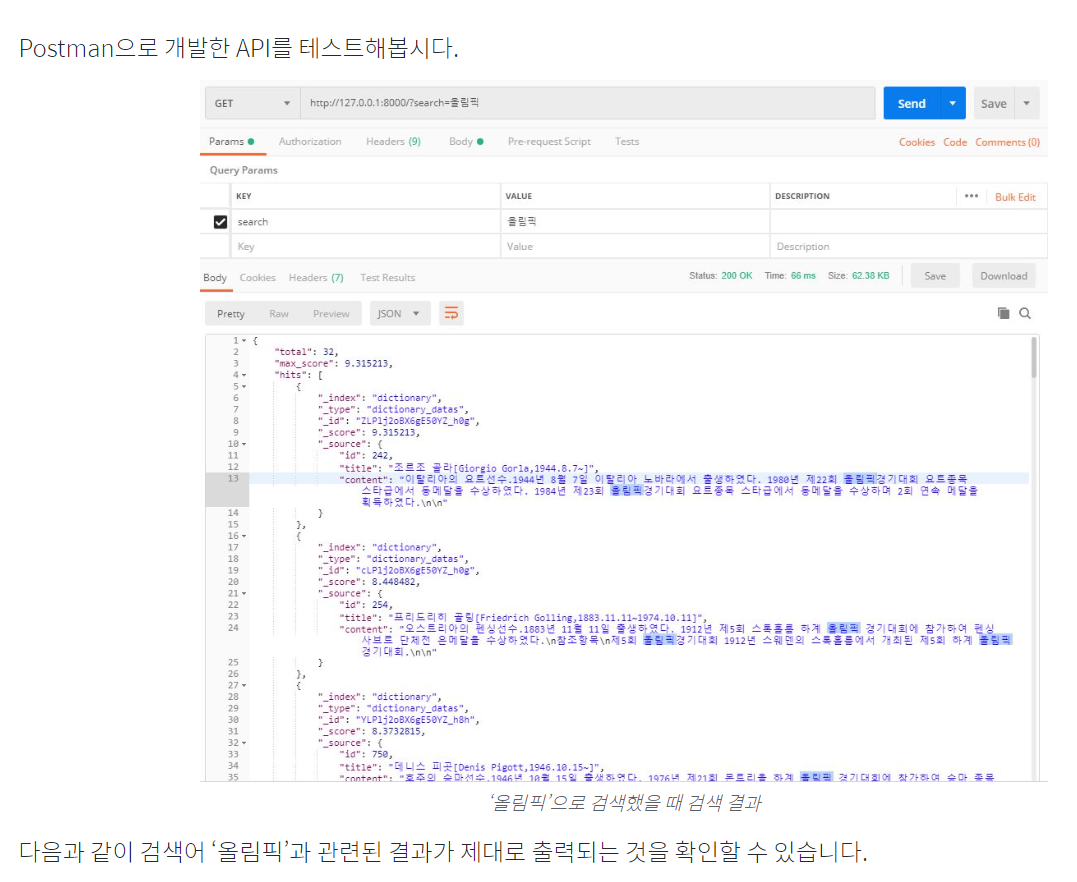

내가 한 결과는 이렇게 나왔는데, Error 메시지에 대한 구글링 결과 apps.py를 실행시키지 않아 Django Server가 열리지 않아 생긴 문제라고 한다.
(아직 갈 길이 멀다..)
728x90'Search Engine' 카테고리의 다른 글
[Search Engine] PageRank (0) 2023.04.30 [검색 엔진 프로젝트] 1. 구글의 검색엔진 알고리즘 (0) 2023.03.19